As an open-source real-time data warehouse, Apache Doris provides a rich choice of indexes to speed up data scanning and filtering. Based on user involvement, they can be divided into built-in smart indexes and user-created indexes. The former is automatically generated by Apache Doris on data ingestion, such as ZoneMap index and prefix index, while the latter is the index users choose for various use cases, including inverted index and NGram BloomFilter index.
This post is a deep dive into inverted index and NGram BloomFilter index, providing a hands-on guide to applying them for various queries.
Sample dataset
The test dataset comprises about 130 million Amazon customer reviews. It is a few Snappy-compressed Parquet files with a total size of 37GB. These are a few samples:

Each row includes 15 columns including customer_id, review_id, product_id, product_category, star_rating, review_headline, and review_body.
A lot of these columns can be accelerated by indexes based on their structures. For example, customer_id is a high-cardinality numerical field while product_id is a low-cardinality fixed-length text field, and product_title and review_body are short and long text fields, respectively.
Queries on these columns can be roughly divided into two types:
- Text searches: searches for certain contents in the
review_bodyfield. - Non-primary key column queries: query reviews about certain
product_idor from certaincustomer_id.
These are also the main threads of this article. I will present to you how indexes can speed up these queries.
Prerequisites
For a quick run, here we use a single-node cluster (1 frontend, 1 backend).
- Deploy Apache Doris: refer to Quick Start
- Create a table using the following statements:
CREATE TABLE `amazon_reviews` (
`review_date` int(11) NULL,
`marketplace` varchar(20) NULL,
`customer_id` bigint(20) NULL,
`review_id` varchar(40) NULL,
`product_id` varchar(10) NULL,
`product_parent` bigint(20) NULL,
`product_title` varchar(500) NULL,
`product_category` varchar(50) NULL,
`star_rating` smallint(6) NULL,
`helpful_votes` int(11) NULL,
`total_votes` int(11) NULL,
`vine` boolean NULL,
`verified_purchase` boolean NULL,
`review_headline` varchar(500) NULL,
`review_body` string NULL
) ENGINE=OLAP
DUPLICATE KEY(`review_date`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`review_date`) BUCKETS 16
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"compression" = "ZSTD"
);
3.Download datasets: Snappy-compressed Parquet files with a total size of 37GB
- amazon_reviews_2010
- amazon_reviews_2011
- amazon_reviews_2012
- amazon_reviews_2013
- amazon_reviews_2014
- amazon_reviews_2015
4.Execute the following commands to load the datasets
curl --location-trusted -u root: -T amazon_reviews_2010.snappy.parquet -H "format:parquet" http://${BE_IP}:${BE_PORT}/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2011.snappy.parquet -H "format:parquet" http://${BE_IP}:${BE_PORT}/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2012.snappy.parquet -H "format:parquet" http://${BE_IP}:${BE_PORT}/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2013.snappy.parquet -H "format:parquet" http://${BE_IP}:${BE_PORT}/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2014.snappy.parquet -H "format:parquet" http://${BE_IP}:${BE_PORT}/api/${DB}/amazon_reviews/_stream_load
curl --location-trusted -u root: -T amazon_reviews_2015.snappy.parquet -H "format:parquet" http://${BE_IP}:${BE_PORT}/api/${DB}/amazon_reviews/_stream_load
5.Check and verify: After the above steps, execute the following statements in the MySQL client to check and see the size of the dataset. It can be seen from below that 135589433 rows are loaded and they take up 25.873GB in Apache Doris, which is 30% smaller than the original Parquet files.
mysql> SELECT COUNT() FROM amazon_reviews;
+-----------+
| count(*) |
+-----------+
| 135589433 |
+-----------+
1 row in set (0.02 sec)
mysql> SHOW DATA FROM amazon_reviews;
+----------------+----------------+-----------+--------------+-----------+------------+
| TableName | IndexName | Size | ReplicaCount | RowCount | RemoteSize |
+----------------+----------------+-----------+--------------+-----------+------------+
| amazon_reviews | amazon_reviews | 25.873 GB | 16 | 135589433 | 0.000 |
| | Total | 25.873 GB | 16 | | 0.000 |
+----------------+----------------+-----------+--------------+-----------+------------+
2 rows in set (0.00 sec)
Accelerate text searches
No index
Now let's try running text searches on the review_body field. Specifically, we're trying to retrieve the top 5 products whose reviews include the keywords "is super awesome". The results should be sorted in descending order based on the number of reviews. Each result should include the product ID, a randomly selected product title, the average star rating, and the total number of reviews.
This is the query statement:
SELECT
product_id,
any(product_title),
AVG(star_rating) AS rating,
COUNT() AS count
FROM
amazon_reviews
WHERE
review_body LIKE '%is super awesome%'
GROUP BY
product_id
ORDER BY
count DESC,
rating DESC,
product_id
LIMIT 5;
Since the review_body field contains lengthy reviews, such text searches can be time-consuming. Without enabling any indexes, it took 7.6 seconds to return the results:
+------------+------------------------------------------+--------------------+-------+
| product_id | any_value(product_title) | rating | count |
+------------+------------------------------------------+--------------------+-------+
| B00992CF6W | Minecraft | 4.8235294117647056 | 17 |
| B009UX2YAC | Subway Surfers | 4.7777777777777777 | 9 |
| B00DJFIMW6 | Minion Rush: Despicable Me Official Game | 4.875 | 8 |
| B0086700CM | Temple Run | 5 | 6 |
| B00KWVZ750 | Angry Birds Epic RPG | 5 | 6 |
+------------+------------------------------------------+--------------------+-------+
5 rows in set (7.60 sec)
Ngram BloomFilter index
Now, let's try accelerating such text searches using the Ngram BloomFilter index.
gram_size: the value of "N" in "Ngram", representing the length of consecutive characters. In the snippet below,"gram_size"="10"means that the texts will be divided into a number of 10-character strings, which are the basis of the Ngram BloomFilter index.bf_size: the size of the BloomFilter in bytes."bf_size"="10240"indicates that the BloomFilter occupies 10240 bytes of space.
ALTER TABLE amazon_reviews ADD INDEX review_body_ngram_idx(review_body) USING NGRAM_BF PROPERTIES("gram_size"="10", "bf_size"="10240");
This time, the query is finished within 0.93 seconds. That means Ngram BloomFilter brings a speedup of 8 times.
+------------+------------------------------------------+--------------------+-------+
| product_id | any_value(product_title) | rating | count |
+------------+------------------------------------------+--------------------+-------+
| B00992CF6W | Minecraft | 4.8235294117647056 | 17 |
| B009UX2YAC | Subway Surfers | 4.7777777777777777 | 9 |
| B00DJFIMW6 | Minion Rush: Despicable Me Official Game | 4.875 | 8 |
| B0086700CM | Temple Run | 5 | 6 |
| B00KWVZ750 | Angry Birds Epic RPG | 5 | 6 |
+------------+------------------------------------------+--------------------+-------+
5 rows in set (0.93 sec)
So how does Ngram BloomFilter do the magic? The way it works can be explained in two parts.
- Ngram tokenization: When
gram_size=5, the phrase "hello world" is split into ["hello", "ello ", "llo w", "lo wo", "o wor", " worl", "world"]. These sub-strings are then hashed and added to a BloomFilter of thebf_size. Since data in Apache Doris is stored by page, the BloomFilters are generated also by page. - Query acceleration: For example, to query the word "hello" in the texts, "hello" is tokenized and compared with the BloomFilters of each page. If the BloomFilter detects a potential match (there might be false positives) in a page, that page is loaded for further matching. Otherwise, that page is skipped.
By skipping the irrelevant pages, the BloomFilter index reduces unnecessary data scanning and thus greatly reduces query latency.
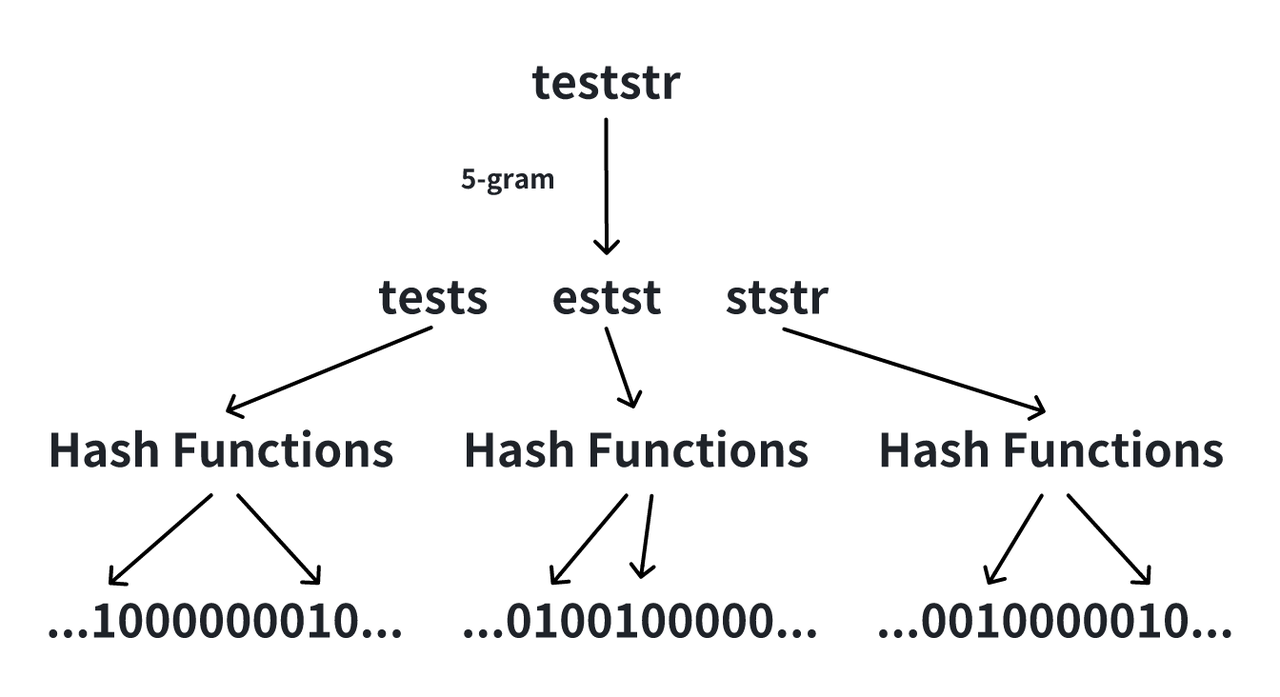
How to find the optimal parameter configurations for Ngram BloomFilter?
gram_size determines the matching efficiency, while bf_size impacts the false positive rate. Typically, a large bf_size reduces the false positive rate but also requires more storage space. Thus, we suggest that you configure these two parameters based on these two factors:
- Text length:
- For short texts (words or phrases), a small
gram_size(2~4) and a smallbf_sizeare recommended. - For long texts (sentences or paragraphs), a large
gram_size(5~10) and a largebf_sizework better.
- For short texts (words or phrases), a small
- Query pattern:
- If the queries often involve phrases or complete words, a large
gram_sizewill be more efficient. - For fuzzy matching or diverse queries, a small
gram_sizeallows more flexible matching.
- If the queries often involve phrases or complete words, a large
Inverted index
Inverted index is another way to accelerate text searches. Creating inverted index is simple:
- Add inverted index: Refer to the snippet below to create inverted index for the
review_bodycolumn of theamazon_reviewstable. Inverted index supports phrase searching, in which the order of the tokenized words will affect the search results. - Add inverted index for historical data: You can also create inverted index for historical data.
ALTER TABLE amazon_reviews ADD INDEX review_body_inverted_idx(`review_body`)
USING INVERTED PROPERTIES("parser" = "english","support_phrase" = "true");
BUILD INDEX review_body_inverted_idx ON amazon_reviews;
3.Check and verify: You can check and see the created indexes using the following statement:
mysql> show BUILD INDEX WHERE TableName="amazon_reviews";
+-------+----------------+----------------+-----------------------------------------------------------------------------------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| JobId | TableName | PartitionName | AlterInvertedIndexes | CreateTime | FinishTime | TransactionId | State | Msg | Progress |
+-------+----------------+----------------+-----------------------------------------------------------------------------------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
| 10152 | amazon_reviews | amazon_reviews | [ADD INDEX review_body_inverted_idx (
review_body
) USING INVERTED PROPERTIES("parser" = "english", "support_phrase" = "true")], | 2024-01-23 15:42:28.658 | 2024-01-23 15:48:42.990 | 11 | FINISHED | | NULL |
+-------+----------------+----------------+-----------------------------------------------------------------------------------------------------------------------------------+-------------------------+-------------------------+---------------+----------+------+----------+
1 row in set (0.00 sec)
If you want to see how tokenization works, you can test with the TOKENIZE function. Just input the text that needs to be tokenized and the parameters:
mysql> SELECT TOKENIZE('I can honestly give the shipment and package 100%, it came in time that it was supposed to with no hasels, and the book was in PERFECT condition.
super awesome buy, and excellent for my college classs', '"parser" = "english","support_phrase" = "true"');
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| tokenize('I can honestly give the shipment and package 100%, it came in time that it was supposed to with no hasels, and the book was in PERFECT condition. super awesome buy, and excellent for my college classs', '"parser" = "english","support_phrase" = "true"') |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ["i", "can", "honestly", "give", "the", "shipment", "and", "package", "100", "it", "came", "in", "time", "that", "it", "was", "supposed", "to", "with", "no", "hasels", "and", "the", "book", "was", "in", "perfect", "condition", "super", "awesome", "buy", "and", "excellent", "for", "my", "college", "classs"] |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.05 sec)
With inverted index, now we retrieve customer reviews containing "is super awesome" using MATCH_PHRASE.
SELECT
product_id,
any(product_title),
AVG(star_rating) AS rating,
COUNT() AS count
FROM
amazon_reviews
WHERE
review_body MATCH_PHRASE 'is super awesome'
GROUP BY
product_id
ORDER BY
count DESC,
rating DESC,
product_id
LIMIT 5;
The clause review_body MATCH_PHRASE 'is super awesome' searches for text fragments in the review_body column that contains all three keywords "is", "super", and "awesome" in that exact order, with no other words in between.
The MATCH query is case-insensitive, which is also what sets it apart from the LIKE query. The MATCH query is more efficient in large datasets.
Results show that inverted index has decreased the query latency to 0.19 seconds, bringing a 4-time performance increase compared to the Ngram BloomFilter index, and a nearly 40-time increase compared to having no indexes at all.
+------------+------------------------------------------+-------------------+-------+
| product_id | any_value(product_title) | rating | count |
+------------+------------------------------------------+-------------------+-------+
| B00992CF6W | Minecraft | 4.833333333333333 | 18 |
| B009UX2YAC | Subway Surfers | 4.7 | 10 |
| B00DJFIMW6 | Minion Rush: Despicable Me Official Game | 5 | 7 |
| B0086700CM | Temple Run | 5 | 6 |
| B00KWVZ750 | Angry Birds Epic RPG | 5 | 6 |
+------------+------------------------------------------+-------------------+-------+
5 rows in set (0.19 sec)
How does inverted index make it possible?
Inverted index splits the texts into words and maps each word to a row number. Then the tokenized words are sorted alphabetically and and a skip list index is created. When executing queries of specific words, the system locates the row numbers in this orderly mapping using the skip list index and binary search methods. Based on the row numbers, the system retrieves the entire data record.
This approach avoids line-by-line matching and reduces computational complexity from O(n) to O(logn). That's how inverted index speeds up queries on large datasets.
To provide a deeper understanding of inverted index, I will start from its read/write logic. In Doris, logically, inverted index is applied at the column level of a table. However, from a physical storage and implementation perspective, it is actually built on data files.
- Writing: When data is written to a data file, it is also synchronously written to the inverted index file, and the row numbers are matched.
- Query: In a query, if the
WHEREcondition involves a column for which an inverted index has been built, Doris will go directly to the index file and returns the corresponding row numbers. Then, based on the row numbers, it skips the irrelevant pages and rows and only reads the target rows.
In short, inverted index enables high-speed text searches by mapping, and its implementation relies on the coordination of data files and index files.
Accelerate non-primary key column queries
To showcase the impact of inverted index on non-primary key column queries, let's try some multi-dimensional queries.
No index
Retrieve the review from Customer ID 13916588 about Product ID B002DMK1R0. Without indexes, the system has to scan the entire table. The query is finished within 1.81 seconds.
mysql> SELECT product_title,review_headline,review_body,star_rating
FROM amazon_reviews
WHERE product_id='B002DMK1R0' AND customer_id=13916588;
+-----------------------------------------------------------------+----------------------+-----------------------------------------------------------------------------------------------------------------------------+-------------+
| product_title | review_headline | review_body | star_rating |
+-----------------------------------------------------------------+----------------------+-----------------------------------------------------------------------------------------------------------------------------+-------------+
| Magellan Maestro 4700 4.7-Inch Bluetooth Portable GPS Navigator | Nice Features But... | This is a great GPS. Gets you where you are going. Don't forget to buy the seperate (grr!) cord for the traffic kit though! | 4 |
+-----------------------------------------------------------------+----------------------+-----------------------------------------------------------------------------------------------------------------------------+-------------+
1 row in set (1.81 sec)
Inverted index
This query is executed in a different way than what is said above, because the system does not have to tokenize the product_id and customer_id, but creates a Value→RowID inverted index table.
First of all, create inverted index via the following statement:
ALTER TABLE amazon_reviews ADD INDEX product_id_inverted_idx(product_id) USING INVERTED ;
ALTER TABLE amazon_reviews ADD INDEX customer_id_inverted_idx(customer_id) USING INVERTED ;
BUILD INDEX product_id_inverted_idx ON amazon_reviews;
BUILD INDEX customer_id_inverted_idx ON amazon_reviews;
With inverted index, the same query is finished within 0.06 seconds. That represents a 30-time higher speed compared to the previous 1.81 seconds.
mysql> SELECT product_title,review_headline,review_body,star_rating FROM amazon_reviews WHERE product_id='B002DMK1R0' AND customer_id='13916588';
+-----------------------------------------------------------------+----------------------+-----------------------------------------------------------------------------------------------------------------------------+-------------+
| product_title | review_headline | review_body | star_rating |
+-----------------------------------------------------------------+----------------------+-----------------------------------------------------------------------------------------------------------------------------+-------------+
| Magellan Maestro 4700 4.7-Inch Bluetooth Portable GPS Navigator | Nice Features But... | This is a great GPS. Gets you where you are going. Don't forget to buy the seperate (grr!) cord for the traffic kit though! | 4 |
+-----------------------------------------------------------------+----------------------+-----------------------------------------------------------------------------------------------------------------------------+-------------+
1 row in set (0.06 sec)
Profile
This is an excerpt of the SegmentIterator Profile, from which you can tell why inverted index accelerates query execution.
(Note that if you need to check the Profile of a query, make sure you have executed SET enable_profile=true; in the MySQL client before you execute the query. Then you can check the Profile at http://FE_IP:FE_HTTP_PORT/QueryProfile)
SegmentIterator:
- FirstReadSeekCount: 0
- FirstReadSeekTime: 0ns
- FirstReadTime: 13.119ms
- IOTimer: 19.537ms
- InvertedIndexQueryTime: 11.583ms
- RawRowsRead: 1
- RowsConditionsFiltered: 0
- RowsInvertedIndexFiltered: 16.907403M (16907403)
- RowsShortCircuitPredInput: 0
- RowsVectorPredFiltered: 0
- RowsVectorPredInput: 0
- ShortPredEvalTime: 0ns
- TotalPagesNum: 27
- UncompressedBytesRead: 3.71 MB
- VectorPredEvalTime: 0ns
RowsInvertedIndexFiltered: 16.907403M (16907403) and RawRowsRead: 1 means that the inverted index has filtered out 16907403 rows and only reads 1 row (the target row). FirstReadTime: 13.119ms means that it takes 13.119 ms to read the page where the target row is located, and InvertedIndexQueryTime: 11.583ms means that the system filters out 16907403 rows within only 11.58 ms.
For comparision, this is the SegmentIterator Profile when no index is used:
SegmentIterator:
- FirstReadSeekCount: 9.374K (9374)
- FirstReadSeekTime: 400.522ms
- FirstReadTime: 3s144ms
- IOTimer: 2s564ms
- InvertedIndexQueryTime: 0ns
- RawRowsRead: 16.680706M (16680706)
- RowsConditionsFiltered: 226.698K (226698)
- RowsInvertedIndexFiltered: 0
- RowsShortCircuitPredInput: 1
- RowsVectorPredFiltered: 16.680705M (16680705)
- RowsVectorPredInput: 16.680706M (16680706)
- RowsZonemapFiltered: 226.698K (226698)
- ShortPredEvalTime: 2.723ms
- TotalPagesNum: 5.421K (5421)
- UncompressedBytesRead: 277.05 MB
- VectorPredEvalTime: 8.114ms
Without inverted index, it takes 3.14s to load 16680706 rows (FirstReadTime: 3s144ms). Then, the system conducts filtering by Predicate Evaluate and screens out 16680705 rows. The conditional filtering process only takes less than 10ms, making original data loading the most time-consuming task.
To sum up, inverted index increases query execution efficiency by enabling quick retrieval of the target rows and thus reducing unnecessary data loading.
Accelerate low-cardinality text column queries
So inverted index is a big accelerator for queries on high-cardinality text columns, but that might raise a concern: For low-cardinality columns, will too many indexes bring excessive overheads and undermine query performance?
The answer is: no. Let me show you why and how. The following example uses product_category as the predicate column for filtering.
mysql> SELECT COUNT(DISTINCT product_category) FROM amazon_reviews ;
+----------------------------------+
| count(DISTINCT product_category) |
+----------------------------------+
| 43 |
+----------------------------------+
1 row in set (0.57 sec)
As is shown, the product_category column has only 43 distinct categories, making it a typical low-cardinality text column. Now, let's add inverted index to it.
ALTER TABLE amazon_reviews ADD INDEX product_category_inverted_idx(`product_category`) USING INVERTED;
BUILD INDEX product_category_inverted_idx ON amazon_reviews;
After adding inverted index, run the following SQL query to retrieve the top 3 products with the most reviews in the "Mobile_Electronics" product category.
SELECT
product_id,
product_title,
AVG(star_rating) AS rating,
any(review_body),
any(review_headline),
COUNT(*) AS count
FROM
amazon_reviews
WHERE
product_category = 'Mobile_Electronics'
GROUP BY
product_title, product_id
ORDER BY
count DESC
LIMIT 10;
With inverted index, the query takes 1.54s to finish.
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------+-------+
| product_id | product_title | rating | any_value(review_body) | any_value(review_headline) | count |
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------+-------+
| B00J46XO9U | iXCC Lightning Cable 3ft, iPhone charger, for iPhone X, 8, 8 Plus, 7, 7 Plus, 6s, 6s Plus, 6, 6 Plus, SE 5s 5c 5, iPad Air 2 Pro, iPad mini 2 3 4, iPad 4th Gen [Apple MFi Certified](Black and White) | 4.3766233766233764 | Great cable and works well. Exact fit as Apple cable. I would recommend this to anyone who is looking to save money and for a quality cable. | Apple certified lightning cable | 1078 |
| B004911E9M | Wall AC Charger USB Sync Data Cable for iPhone 4, 3GS, and iPod | 2.4281805745554035 | A total waste of money for me because I needed it for a iPhone 4. The plug will only go in upside down and thus won't work at all. | Won't work with a iPhone 4! | 731 |
| B002D4IHYM | New Trent Easypak 7000mAh Portable Triple USB Port External Battery Charger/Power Pack for Smartphones, Tablets and more (w/built-in USB cable) | 4.5216095380029806 | I bought this product based on the reviews that i read and i am very glad that i did. I did have a problem with the product charging my itouch after i received it but i emailed the company and they corrected the problem immediately. VERY GOOD customer service, very prompt. The product itself is very good. It charges my power hungry itouch very quickly and the imax battery power lasts for a long time. All in all a very good purchase that i would recommend to anyone who owns an itouch. | Great product & company | 671 |
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------+-------+
3 rows in set (1.54 sec)
Now let's try again without enabling inverted index. The same query takes 1.8s to finish. (You can simply disable inverted index by executing set enable_inverted_index_query=false; in the MySQL client.)
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------------+-------+
| product_id | product_title | rating | any_value(review_body) | any_value(review_headline) | count |
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------------+-------+
| B00J46XO9U | iXCC Lightning Cable 3ft, iPhone charger, for iPhone X, 8, 8 Plus, 7, 7 Plus, 6s, 6s Plus, 6, 6 Plus, SE 5s 5c 5, iPad Air 2 Pro, iPad mini 2 3 4, iPad 4th Gen [Apple MFi Certified](Black and White) | 4.3766233766233764 | These cables are great. They feel quality, and best of all, they work as they should. I have no issues with them whatsoever and will be buying more when needed. | Just like the original from Apple | 1078 |
| B004911E9M | Wall AC Charger USB Sync Data Cable for iPhone 4, 3GS, and iPod | 2.4281805745554035 | I ordered two of these chargers for an Iphone 4. Then I started experiencing weird behavior from the touch screen. It would select the wrong area of the screen, or it would refuse to scroll beyond a certain point and jump back up to the top of the page. This behavior occurs whenever either of the two that I bought are attached and charging. When I remove them, it works fine once again. Needless to say, these items are being returned. | Beware - these chargers are defective | 731 |
| B002D4IHYM | New Trent Easypak 7000mAh Portable Triple USB Port External Battery Charger/Power Pack for Smartphones, Tablets and more (w/built-in USB cable) | 4.5216095380029806 | I received this in the mail 4 days ago, and after charging it for 6 hours, I've been using it as the sole source for recharging my 3Gs to see how long it would work. I use my Iphone A LOT every day and usually by the time I get home it's down to 50% or less. After 4 days of using the IMAX to recharge my Iphone, it finally went from 3 bars to 4 this afternoon when I plugged my iphone in. It charges the iphone very quickly, and I've been topping my phone off (stopping around 95% or so) twice a day. This is a great product and the size is very similar to a deck of cards (not like an iphone that someone else posted) and is very easy to carry in a jacket pocket or back pack. I bought this for a 4 day music festival I'm going to, and I have no worries at all of my iphone running out of juice! | FANTASTIC product! | 671 |
+------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------------+-------+
3 rows in set (1.80 sec)
To sum up, inverted index can bring a 15% speedup for queries on low-cardinality columns. So it is not only harmless but also beneficial to low-cardinality data filtering.
In addition, Apache Doris adopts effective dictionary encoding and compression for low-cardinality columns. It also utilizes built-in indexes like ZoneMap for filtering. Thus, it can deliver ideal query performance even without inverted indexes.
Conclusion
Inverted index in Apache Doris optimizes data filtering based on the predicate column (the WHERE clause in SQL queries). It reduces unnecessary data scanning and significantly increases query speed on high-cardinality columns and guarantees no negative effects on low-cardinality columns. It supports lightweight index management, including ADD/DROP INDEX and BUILD INDEX. It can be easily enabled or disabled via enable_inverted_index_query=true/false.
Inverted index and NGram BloomFilter index apply to different scenarios. This is how you decide which one is the optimal choice:
- Non-primary key column queries: These cases often involve widely scattered values and a low hit rate. Inverted index can work in conjunction with the built-in smart indexes in Doris to accelerate these queries. It has well-established support for scalar data types including characters, numerics, and datetime.
- Text searches on short texts: If the dataset includes short texts that are highly diverse, NGram BloomFilter will be an effective choice for fuzzy matching (
LIKE) on short texts. If the short texts are very similar (with lots of identical content), inverted index will be more efficient because it ensures a smaller dictionary and faster retrieval of the row numbers. - Text searches on long texts: Inverted index is a better choice for long texts. Compared to brutal-force string matching, it largely reduces CPU resource consumption.
Inverted index has been available in Apache Doris for almost a year and stood the test of many users in their production environment with massive data. In future versions of Apache Doris regarding inverted index, we plan to add support for:
- Self-defined tokenization: provides a user-defined tokenizer to fit in different use cases.
- More data types: Users will be able to create inverted index for complex data types including Array and Map.
If you encounter any issues while trying it out in Apache Doris or would like to know more details, join our Slack community and talk to us!