- Products
- Solutions
- Resources
- Company
- Pricing
- Contact Us
Start Free
Unified
One Platform for Various Analytics Workloads
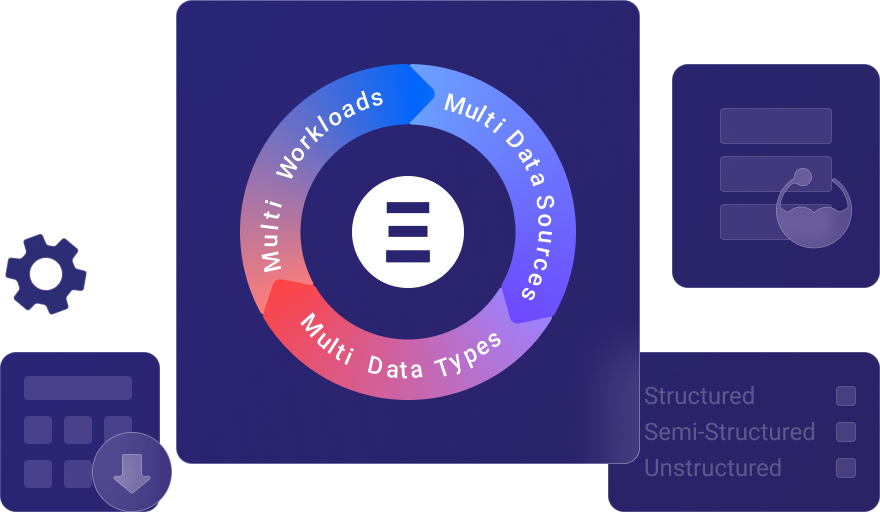
All-in-one analytics platform
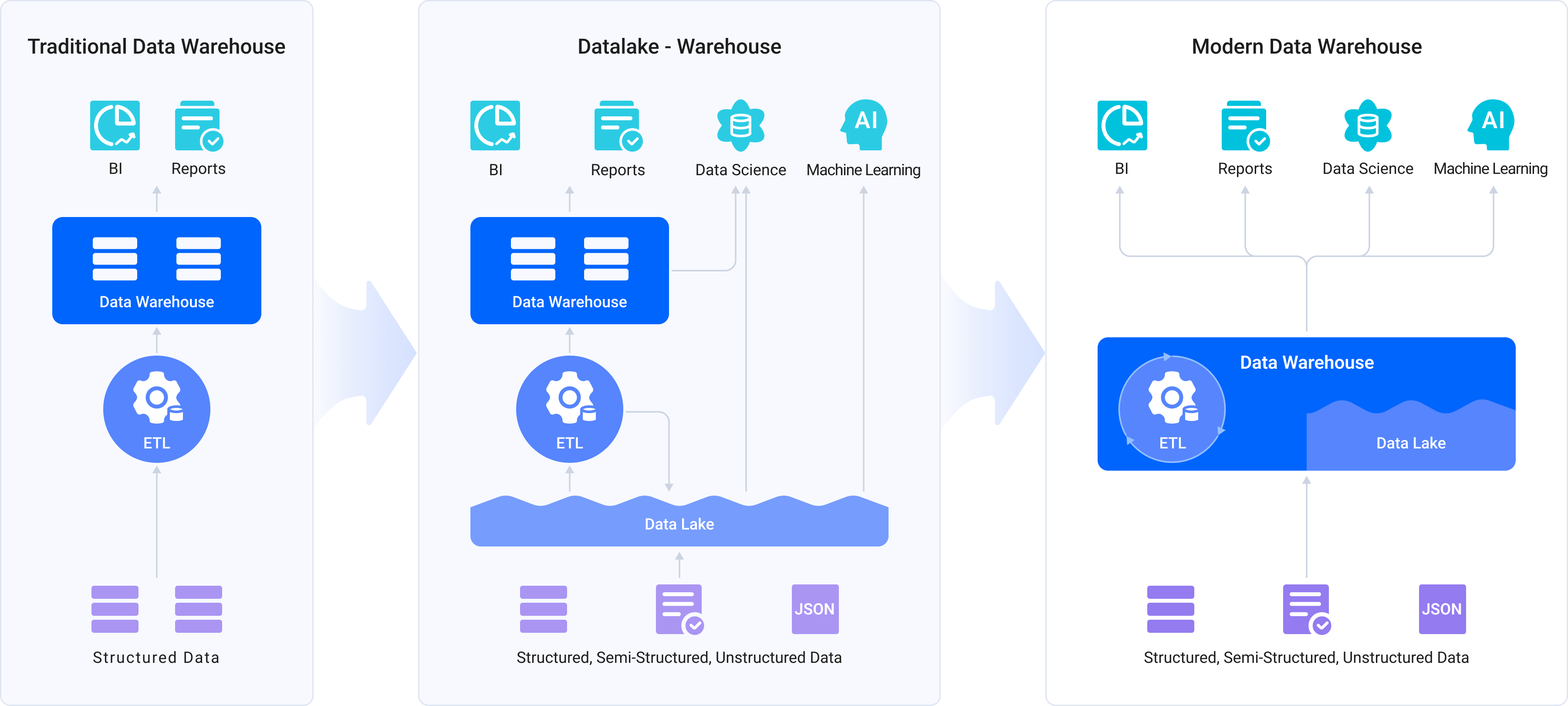
The big data industry abounds in specialized tools and technologies, but when companies need to deploy a long list of components for their diverse analytics needs, they are often haunted by problems like arduous maintenance, complicated pipelines, and redundant storage.
As a modern data warehouse, VeloDB supports a wide range of data sources, data types and analytics workloads. An all-in-one analytics platform is much easier to operate and can help companies redirect their energy from maintaining data infrastructure to improving their data applications.
Key capabilities
Query data from external data lakes and databases via multi-catalog
- Rich lake types: HDFS, object storage; Hive, Iceberg, Hudi; HMS, Glue etc.
- Various integration methods: catalog mapping, database/table mapping, table-valued function
- Federated queries and data transfer between internal and external sources
Not just structured data, but also semi-structured data and texts
- Compound data types such as Array, Map, and JSON
- Variant data type to support auto data type inference of JSON data
- NGram BloomFilter and inverted index for text searches
Not just real-time analytics, but also ELT in database (to be released)
- ELT in VeloDB instead of relying on external Spark or Flink
- Incremental data reading: support incremental data reading
- Incremental data processing: faster than Spark, easier than Flink